
記事の要点
・日立製作所が、日々の企業活動で生成・蓄積されるものの有効活用できていない膨大な「ダークデータ」に着目した「データ抽出ソリューション」の提供を開始。
・AIを中核としたダークデータ分析エンジンを活用し、請求書や診療明細書といった、発行元によって様式や表記が異なる非定型ドキュメントの利活用において、取得したいデータの抽出作業を自動化・高度化する。
・今後は、企業が保有するダークデータ全般に対応するソリューションの実現に向け、AIの抽出機能をさらに強化し、社会や企業におけるデータ利活用による新たな価値の創出や課題解決を支援する。
LoveTechポイント
ダークデータの問題は、大企業だけでなく中小企業でも根が深いものだからこそ、潜在ニーズ含めて引き合いは非常に多いのではないかと感じます。
だからこそ、より多くの企業が導入できるような提供形態と価格プランの設定が、今後さらに求められると思います。
編集部コメント
株式会社日立製作所が、日々の企業活動で生成・蓄積されるものの有効活用できていない膨大なデータである「ダークデータ」に着目した「データ抽出ソリューション」の提供を開始した。

昨今、IoTの進展によって社会や企業活動から生み出されるデータ量は加速度的に増え続けており、組織がもつ膨大なデータの多くは、活用されないままダークデータとして眠っている状況だ。
逆に捉えると、この日々蓄積されるダークデータを「意味ある情報」として整理・分析することで、新しい価値の創出につながり、今後のビジネス拡大に向けた打ち手になりうるとする指摘は多い。
例えばフォーマットが決まっている帳票類については、AI-OCR技術によるデータ化ができるので、神の情報をデジタルデータとして利活用できるようになってきている。
一方で、請求書や診療明細書、有価証券報告書などといった非定型ドキュメントは、発行元や運用部署によって表記や様式が異なるため、読み取り・抽出の自動化が困難なケースが多く、課題となっている。
そんななか日立は、2016年より、スタンフォード大学工学系研究科が主催するデータサイエンス分野におけるプログラム「Stanford Data Science Initiative」に参画し、ダークデータの効率的な活用に向けた研究を実施。その成果をオープンソースとして公開してきた。
また、同社のデータサイエンティストのトップ人財が集まる「Lumada Data Science Lab.」では、ダークデータに関する専任の研究開発チームも設置しており、最新の研究やテクノロジーを活用したソリューション開発に取り組んでいる。
今回、その研究開発の成果として、先述のような非定型ドキュメントであっても取得したいデータの抽出作業を自動化・高度化できる「データ抽出ソリューション」をリリースしたというわけだ。
特徴は大きく2点。
まずは、高度な解析技術を活用し、様々な非定型ドキュメントからのデータ抽出を効率化できる点だ。
人が文書を読むとき、認識しているのは文字情報だけではない。全体のレイアウトや単語の出現位置など、視覚的な情報からも文書を捉えていることは、おわかりいただけるだろう。このような視覚的情報についても、AIが表や図、テキストの座標といったドキュメント内のさまざまな特徴認識し、文書の構造全体を解析するので、非定型のフォーマットでも認識ができるようになっている。
これにより、人手でかかる抽出後のデータ処理時間を削減し、得られたデータを迅速に業務改革に活用するなど、より高度な業務にリソースを充てることができるようになるというわけだ。
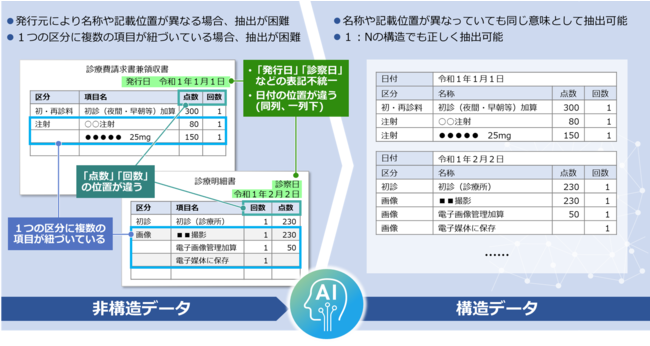
診療明細書を使ったデータ抽出のイメージ。たとえば、日付の表記が「発行日」と「診察日」など、発行元によって異なる用語が使われている場合、文書の構造から同じ意味をさす単語としての認識が可能で、抽出対象が複数ページにまたがるドキュメントでも、対象となる項目を抽出することができる。また、一つの区分に対して複数の項目が紐づく1:Nの関係も正しく認識するため、複雑な表のデータ抽出にも適している
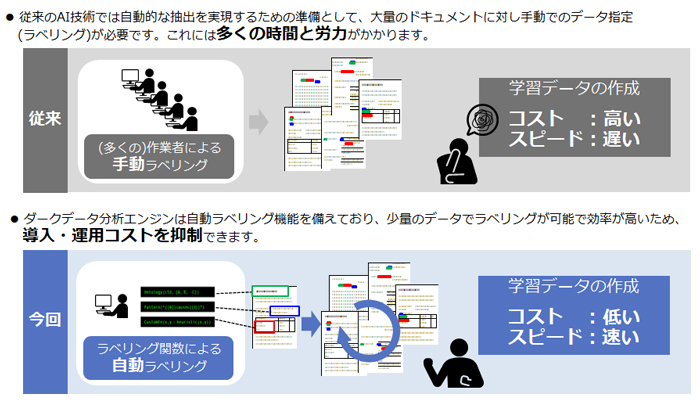
もう一つの特徴は、少ないデータからAIモデルを構築する技術により、導入時・改定時の作業負荷や期間を削減できること。
従来のAI技術は、モデル構築にあたって大量の学習データを準備し、人手でデータのラベリングを行うことが一般的である。そのため、モデルの構築や精度の維持・運用に多大なコストと時間が必要なのだが、本ソリューションでは、少ない学習データでAIモデルを生成できる「弱教師学習技術(Weakly Supervised Learning)」により、データのラベリング作業を自動化を実現している。
これにより、モデル構築のための期間短縮やコスト削減が可能となるほか、追加学習や再学習といったモデルの継続的な改善にも柔軟に対応できるため、導入時だけでなく、法改正や商品改定にも迅速に対応でき、運用の効率化が期待できる。
サービスの導入時には、日立の専門エンジニアが実際の業務で扱うドキュメントに適したモデルの構築を行うなど、業務内容に応じた最適な導入・運用のコンサルティングを行う。また、他システムとのシームレスなデータ連携を可能にするAPIによって、既存のOCRシステムや業務システムとの連携も効率化が可能だ(価格は個別見積)。
今後、同社は、画像や映像、音声といった、企業が保有するダークデータ全般に対応するソリューションの実現に向け、AIの抽出機能をさらに強化し、同社のLumada(※)ソリューションの一つとして、社会や企業におけるデータ利活用による新たな価値の創出や課題解決を支援していくという。
※クライアントの持つデータから価値を創出し、デジタルイノベーションを加速するための、日立の先進的なデジタル技術を活用したソリューション・サービス・テクノロジーの総称
同社ではこれまでも、独自のAI-OCR技術による帳票認識サービスを提供しており、定型・非定型双方の帳票の文字認識と、それに伴うソリューションの提供を行ってきた。
今回発表されたサービスは、米国の技術を応用して企業内のダークデータ抽出にフォーカスしているとのことで、より人の手を介さない形で、データドリブン施策の基盤を整えることができることになる。
大企業だけでなく中小企業でもダークデータ問題は根深いであろうからこそ、より多くの企業が導入できるような提供形態と価格感が、今後さらに求められるだろう。










